Introduction
对于一个基于 CTR 预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。在不同的推荐场景中,低阶或者高阶组合特征都可能会对最终的 CTR 产生影响。
Wide & Deep Learning 通过组合使用 cross-product transformation 特征的线性模型和 DNN 模型进行 Joint train 从而实现 memorization 和 generalization 的结合。但是对于 Wide 模型来说还是需要做一些特征交叉来实现 memorization,比如因子分解机 (Factorization Machines, FM) 通过对每一维特征隐变量进行内积提取组合特征,进而获得较好的预测效果。虽然理论上 FM 可以对高阶特征组合进行建模,但由于计算复杂度等原因在实践中一般都只用到二阶特征组合。 关于 Wide & Deep Learning 请参考博文:Wide & Deep Learning模型介绍
对于高阶的特征组合来说,通过多层的神经网络即 DNN 来处理是一个很自然的想法。 另一方面,对于离散特征而言,一种常见的处理方法是将特征转换成为 Onehot 的形式。 然而,将 Onehot 类型的特征输入到 DNN 中会由于网络参数太多而影响训练[1]:
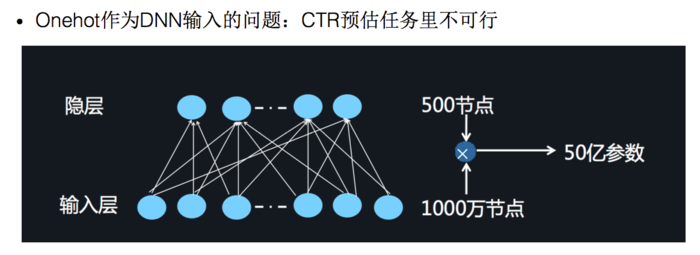
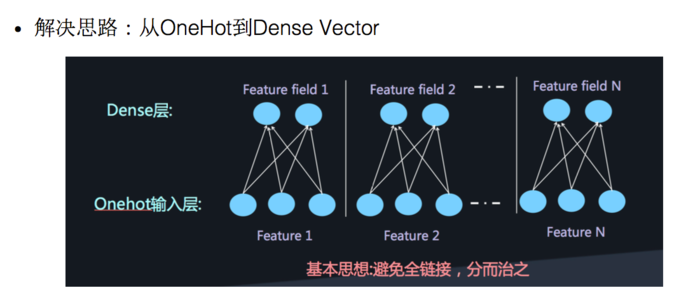
通过借鉴 word2vec 的思路进行 embedding,将 Onehot 编码后的向量经过一个 embedding 层输出 Dense Vector 是一种比较实用的方法。具体的思路是将一个特征 Onehot 编码后会生成多个特征,但是每个特征里面只有一个为 $1$,其他都为 $0$,这些由一个特征生成的多个互斥的特征在 FFM 方法中属于一个 Field。
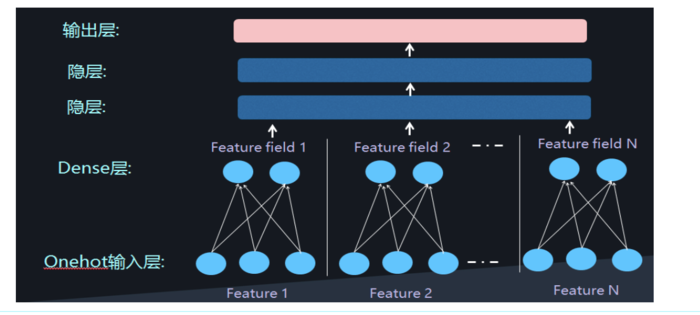
如果将 embedding 层的输出再加两层全连接层,让 Dense Vector 进行组合就完成了高阶特征的组合。
但是低阶和高阶特征组合都深度耦合体现在隐藏层中,因此需要对低阶特征组合单独建模,而后再融合高阶特征组合。
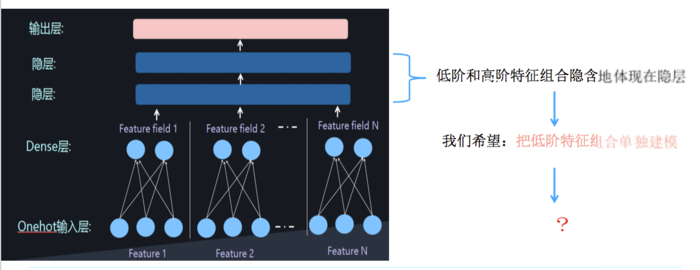
这意味着在学习低阶的特征组合的同时,也需要学习高阶的特征组合,即将 DNN 与 FM 进行一个合理的融合:
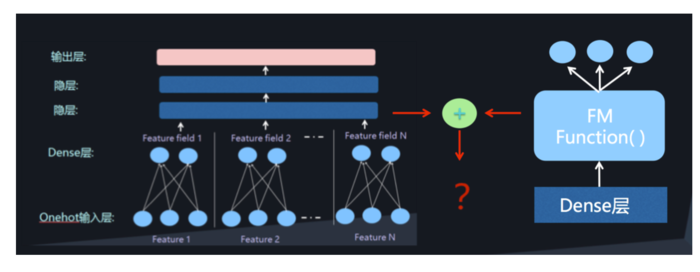
二者的融合总的来说有两种形式,串行结构与并行结构
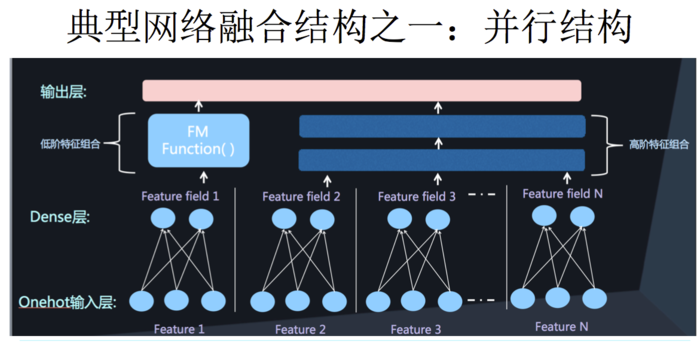
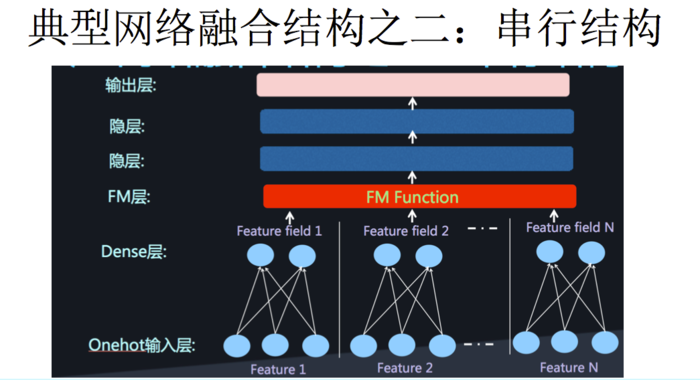
而 DeepFM,就是并行结构中的典型代表。
DeepFm 模型 [2]
模型结构
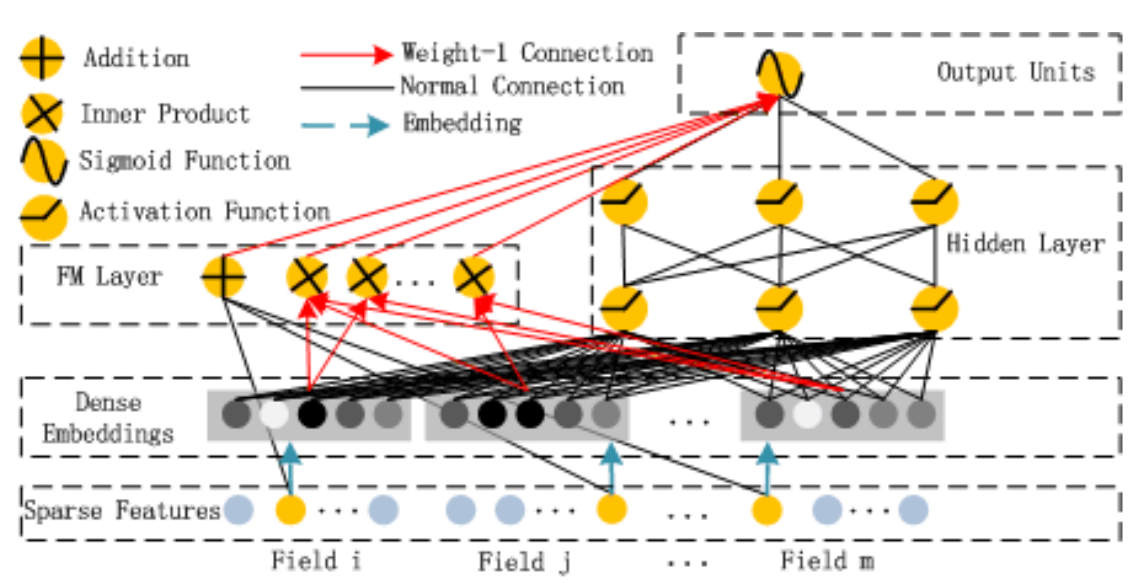
DeepFM 包含两部分:神经网络与因子分解机,分别负责提取低阶特征和高阶特征。(PS: 这两部分当然共享同样的输入)。同时,DeepFM 的预测结果为:
$$ \hat y = sigmoid({y_{FM}} + {y_{DNN}})\tag1 $$
FM Component
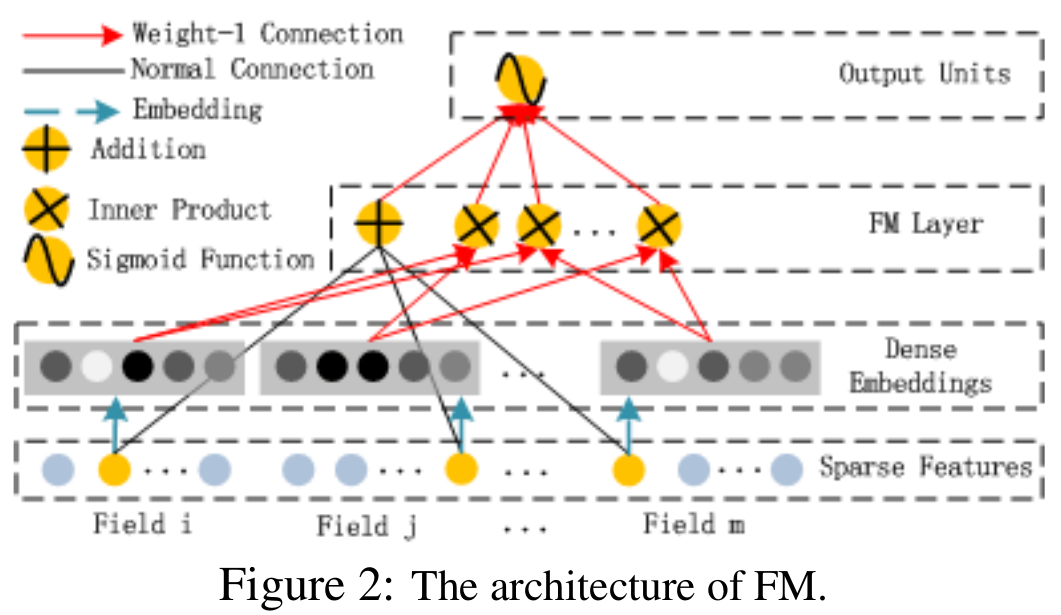
FM (详情可参阅文章[3])因为引入了隐变量的原因,对于几乎不出现或者很少出现的隐变量,也可以进行很好的学习。
FM的输出为:
$$ y(x)=w_{0}+\sum_{i=1}^{n}\left(w_{i} x_{i}\right)+\sum_{i=1}^{n-1} \sum_{j=i+1}^{n}\left(\left\langle v_{i}, v_{j}\right\rangle x_{i} x_{j}\right)\tag{2} $$
Deep Component
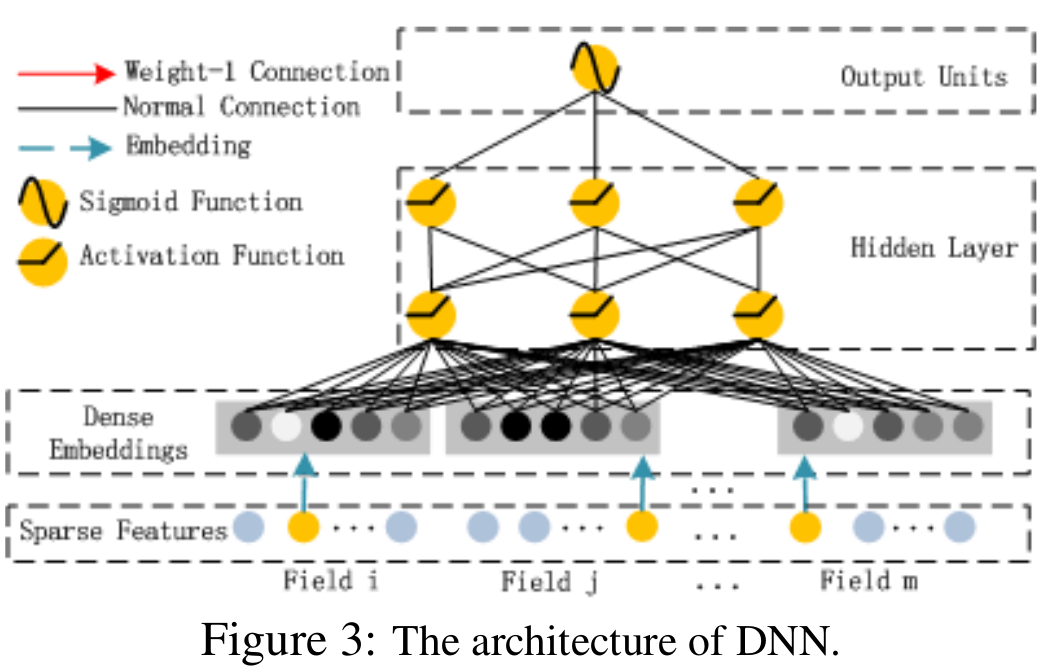
深度部分是一个前馈神经网络,与图像或者语音这类输入不同的是图像语音的输入一般是连续而且密集的。然而,用于 CTR 的输入一般是极其稀疏的,需要重新设计网络结构以适应相应的数据特点。因此,通过在第一层隐藏层之前引入一个嵌入层 (embedding layer) ,从而完成将输入向量压缩到低维稠密向量的过程,其结构如下图所示。
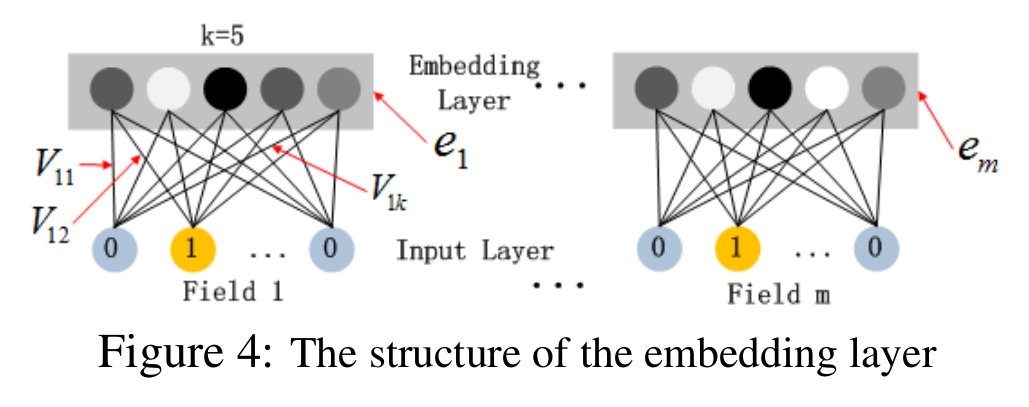
对于 Fig.4 这个网络结构有两个很有意思的 points:
-
虽然输入的 field vector 长度不一,但是它们 embedding 出来的长度是固定的;
-
FM 的 latent vector $V$ 向量作为原始特征到 embedding vector 的权重矩阵被放在网络里学习。
这里的第二点如何理解呢?在假设 $k=5$ 的前提下,首先对于输入的一条记录,同一个 Field 只有一个位置是 1,那么在由输入得到 dense vector 的过程中,输入层只有一个神经元起作用,得到的 dense vector 其实就是输入层到 embedding 层该神经元相连的五条线的权重,即 $v_{i1}$,$v_{i2}$,$v_{i3}$,$v_{i4}$,$v_{i5}$。这五个值组合起来就是在 FM 中所提到的 $v_i$。在 FM 部分和 DNN 部分,这一块是共享权重的,因此对同一个特征来说得到的 $V_i$ 是相同的。